在人工智能领域,大模型的推理能力一直是研究者们关注的焦点。近日,一项来自图宾根马普所(马克斯・普朗克生物控制论研究所)的研究为Transformer架构带来了全新的变革,通过引入递归思想,让模型在预训练阶段就能具备深度推理的能力。这一成果不仅为小规模模型的能力提升提供了新路径,也为AI系统的“思考”能力带来了激动人心的突破。
据悉,该研究团队在Transformer架构中引入了一个核心创新——允许同一组参数被重复使用。这一改变打破了传统Transformer架构中一次性计算的限制,使得信息可以在同一个跑道上反复奔跑,从而增强了模型的推理能力。这种被重复使用的参数组被研究人员称为循环核心,它为一个仅为4层的神经网络。整个新Transformer的架构被分为预奏-核心-尾声(Prelude-Core-Coda)三个部分,其中预奏和尾声相当于编码器和解码器,负责将输入的文本转换成特殊表示以及将模型的思考结果转换回人类可以理解的形式。
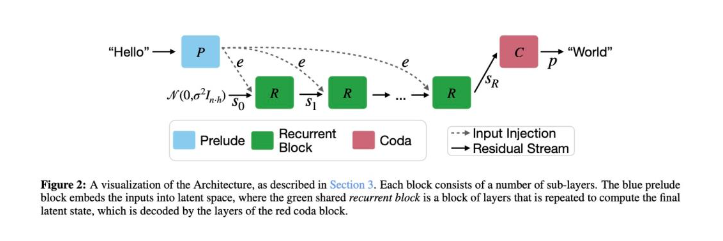
循环核心块的工作原理类似于一个大脑,它从一个随机的思维状态开始,结合经过前奏处理的问题信息,通过自注意力机制和交叉注意力机制整理当前的思维状态,并将问题信息与当前的思维状态结合起来。然后,通过一个前馈网络进行深入处理,产生一个新的思维状态。这个思考过程会反复进行,每一轮思考都会产生一个新的状态,直到模型得出最终的答案。
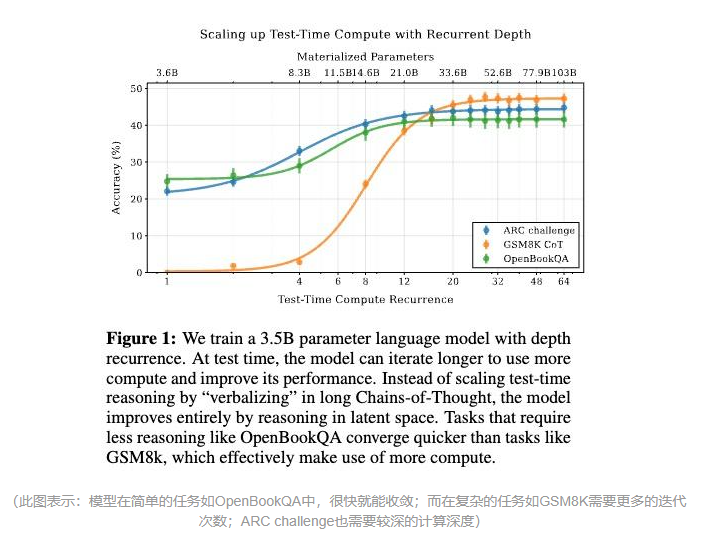
在实验中,研究人员发现,这种递归深度架构的模型展现出了与DeepSeek R1相似的“思考时间的自适应性”。对于简单的问题,模型只需要较少的迭代次数就能得出答案,而对于复杂的问题,迭代次数会自动增加。这一特性表明,模型确实展现出了深度推理思考的特征。
为了验证模型的推理能力,研究人员采用了“结构相似,表面不同”的测试策略,将一些经典问题改编成变体问题。实验结果显示,模型依然能够准确地解答这些变体问题,这表明模型真正掌握了推理能力,而不是简单地记忆训练数据。
此外,研究人员还开发了一种新技术来可视化模型的“思维过程”。他们将模型的内部状态投影到二维平面上,创建了类似于“思维地图”的可视化图像。这些图像揭示了模型在处理不同问题时所经历的推理路径和思维状态的变化。通过分析这些图像,研究人员发现,模型在处理复杂问题时,其思维状态会呈现出反复振荡的模式,这表明模型在进行多层次的语义理解。
这一研究成果的意义重大。首先,它为小规模模型的能力提升提供了除蒸馏之外的另一个有潜力的路径。其次,它开创了一条除强化学习以外,增强模型推理能力的新路。更重要的是,它和DeepSeek R1一样,提供了一种模型不依靠直接范例,自我生成推理能力的可能。这种“纯推理”路径为AI系统的发展带来了新的方向。
值得注意的是,目前这个3.5B参数的初代模型虽然还很稚嫩,但它已经展示了惊人的潜力。仅通过增加推理深度,它就能在某些任务上达到50B参数模型的表现。这一成果不仅证明了递归深度架构的有效性,也为未来的研究提供了广阔的空间。